
COLUMN
【Intel® アクセラレーションカード開発日誌 #3】Intel® アクセラレーションカードの実力を知る
前回はIntel® Programmable Acceleration Card(以降Intel® アクセラレーションカードと呼称)を動かす準備を進めました。今回は、実際にIntel® アクセラレーションカードを動かし、どのぐらいの速度が出るのか測定した上で、Intel® アクセラレーションカードで効果が出そうなアプリケーションの考察を行います。
Hello, FPGA!
さて、Firmwareを最新にしたIntel® アクセラレーションカードを動かす第一歩としては、FPGA診断プログラムの実行から入りたいと思います。
今回もIntel® Acceleration Stack Quick Start Guideを参照しながら進めていきます。
とりあえずはHello FPGAサンプルを実行してみましょう。
何事もHello *** は最初の第一歩として大事ですね。
このサンプルでは、最初にfpgaconf コマンドを使ってnlb_mode_0というサンプルAFUイメージをロードしています。
この時点ではFPGAに回路を読み込んだだけなので、まだ何も実行されていません。
その後、hello_fpga.cをgccでbuildし、実行しています。
結果は以下のように表示されました。
Using OPAE C library version ‘1.1.2’ build ‘d65c3a3’
Running Test
Running on bus 0xD8.
Done Running Test
このように、Intel® アクセラレーションカードの環境では、AFUデザインとLinuxソフトウェアという2つのバイナリをそれぞれ生成し、あらかじめAFUデザインをIntel® アクセラレーションカードにロードした上で、それを動かすソフトウェアを実行する、という流れになります。これは今後の開発でも変わりません。
Acceleration Stackでは、さらにいくつかのサンプルAFUデザインと診断プログラムが用意されています。診断プログラムはfpgabistというコマンドで、現状ではnlb_mode_3とdma_afuというAFUデザインのみ受け付けるようです。コマンドの詳細は以下のページに記載されています。
https://opae.github.io/1.0.2/docs/fpga_tools/fpgabist/fpgabist.html
Quick Start Guideに従い、nlb_mode_3というサンプルAFUデザインを使って実行してみましょう。
Testは完了しましたが、ログに以下の記録がありました。
Running fpgadiag write test…
Exception caught: stoi – could not convert d8 to a number
Exception caught: stoi – could not convert d8 to a number
これはQuick Start Guideに記載されている通り、/usr/bin/bist_nlb3.pyの修正が必要です。それにより、エラーなく最後まで完了しました。
用意された2つのDMAデザインのサンプル
さて、ここまでで試したサンプルAFUデザインはいずれもNLB(ネイティブループバック)と呼ばれていて、AFUの内部処理は何も行わずに、単純にデータをメモリにWriteしてReadするだけのテストです。
それ以外に、DMAが可能なサンプルAFUデザインも入っています。DMA(ダイレクトメモリアクセス)は、AFU内部のDMAコントローラ自身が主役となり、ホストとの共有メモリやIntel® アクセラレーションカードに搭載されたローカルメモリのデータを読み書きするものです。ハードウェアが直接処理するために極めて高速で、初期設定さえ終わればソフトウェアの介在無しでずっとデータ転送を続けられます。実際のアプリケーションでもDMAが基本的な処理系なので、このサンプルAFUデザインは実際のアプリケーション開発のベースデザインとも言えます。
用意されているDMAのサンプルAFUデザインは、dma_afuとstreaming_dma_afuの2種類です。
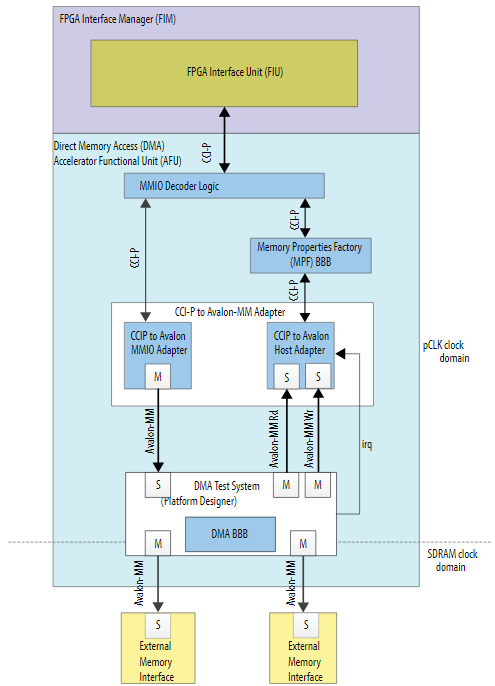 図1 dma_afuのブロック図dma_afuは、ホスト側のメモリからIntel® アクセラレーションカードの外部メモリへ、およびIntel® アクセラレーションカードの外部メモリからホスト側のメモリへデータをDMAするデザインです(図1)。各DMAは同時に行わず、シリアルに処理されます。メモリへのアクセスは、DMAのソース側もディスティネーション側もAvalon-MMというMemory Mapped Accessで行われます。
図1 dma_afuのブロック図dma_afuは、ホスト側のメモリからIntel® アクセラレーションカードの外部メモリへ、およびIntel® アクセラレーションカードの外部メモリからホスト側のメモリへデータをDMAするデザインです(図1)。各DMAは同時に行わず、シリアルに処理されます。メモリへのアクセスは、DMAのソース側もディスティネーション側もAvalon-MMというMemory Mapped Accessで行われます。
このDMA形式は、画像処理や圧縮、ハッシュ生成など、データを一区切りごとに処理する場合のデザインに向いています。
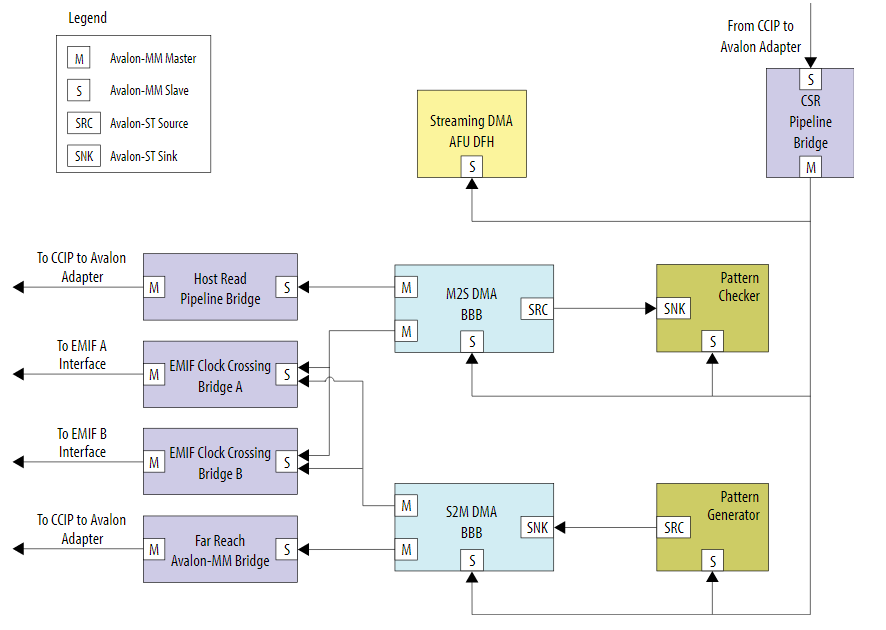 図2 streaming_dma_afuのブロック図streaming_dma_afuは、Intel® アクセラレーションカードの外部メモリを使わず、AFU内で生成したデータをホスト側メモリに転送してコンペア、およびホスト側メモリに生成したデータをAFU内に転送してコンペアするものです(図2)。各DMAは同時に行わず、シリアルに処理されます。DMAにおけるホストメモリへのアクセスはAvalon-MMというMemory Mapped Accessですが、FPGA内部向けにはAvalon-STというStreaming型のデータバスで構成されており、パターンジェネレーターとパターンチェッカーが接続されています。
図2 streaming_dma_afuのブロック図streaming_dma_afuは、Intel® アクセラレーションカードの外部メモリを使わず、AFU内で生成したデータをホスト側メモリに転送してコンペア、およびホスト側メモリに生成したデータをAFU内に転送してコンペアするものです(図2)。各DMAは同時に行わず、シリアルに処理されます。DMAにおけるホストメモリへのアクセスはAvalon-MMというMemory Mapped Accessですが、FPGA内部向けにはAvalon-STというStreaming型のデータバスで構成されており、パターンジェネレーターとパターンチェッカーが接続されています。
このDMA形式は、映像や音声、ネットワークなど連続したデータの処理を行う際にベースになります。
DMAを実行してみる
それでは、dma_afuを動かしてみましょう。
デザインは以下のパスに入っています。
$OPAE_PLATFORM_ROOT/hw/samples/dma_afu
すでに生成済みのgbsファイルも、上記パスのbinディレクトリの中にあります。このgbsファイルをfpgaconf コマンドでロードしておきます。
$ sudo fpgaconf $OPAE_PLATFORM_ROOT/hw/samples/dma_afu/bin/dma_afu.gbs
同様に、swというディレクトリにあるコードをmakeすると、テスト処理プログラムが生成できるようです。
$ cd $OPAE_PLATFORM_ROOT/hw/samples/dma_afu/sw
$ make
さあ、実行してみましょう。
$ sudo ./fpga_dma_test 0
結果は以下のように表示されました。
Running test in HW mode
Buffer Verification Success!
Buffer Verification Success!
Running DDR sweep test
Buffer pointer = 0x7f7d27a91000, size = 0x100000000 (0x7f7d27a91000 through 0x7f7e27a91000)
Allocated test buffer
Fill test buffer
DDR Sweep Host to FPGA
Measured bandwidth = 6882.501753 Megabytes/sec
Clear buffer
DDR Sweep FPGA to Host
Measured bandwidth = 6184.027740 Megabytes/sec
Verifying buffer..
Buffer Verification Success!
(中略)
Verifying buffer..
Buffer Verification Success!
Finished Executing DMA Tests
このように、サイズとアドレス、転送レートが表示されます。
なんとなく、パラメータを変更できそうな気がしますね。パラメータをいろいろ変えてみましょう。
DMA転送レートの測定と考察
fpga_dma_test.c というファイルの中の、以下の行を変更すれば転送サイズを変更できそうです。この例だと4GByteですね。
ssize_t total_mem_size = (uint64_t)(4 * 1024) * (uint64_t)(1024 * 1024);
転送サイズをいろいろ変えて測定したものが、以下の図3になります。
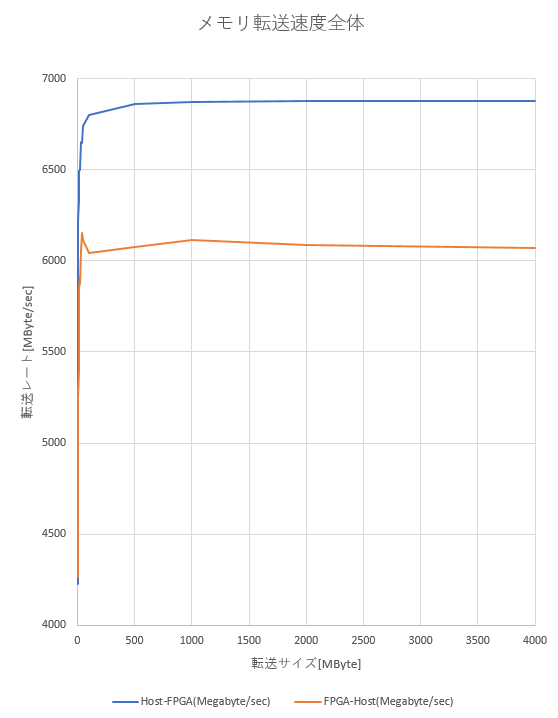 図3 DMA転送速度のグラフ転送サイズが大きくなると転送レートが向上し、1Gbyteを超えると安定しています。これはDMA開始と終了時のオーバーヘッドの時間が、データサイズが大きくなるほど希釈されると考えると妥当です。
図3 DMA転送速度のグラフ転送サイズが大きくなると転送レートが向上し、1Gbyteを超えると安定しています。これはDMA開始と終了時のオーバーヘッドの時間が、データサイズが大きくなるほど希釈されると考えると妥当です。
転送サイズが100MByteあたりで、FPGA-Host転送が妙に転送レートが良い瞬間があります。これは転送前後のオーバーヘッドの時間の方が実際の転送時間よりかかるような場合に、たまたまホストメモリの領域確保(memalloc)などが早く終わった、または時間がかかったなどの理由でばらつきが出たためだと思われます。
とりあえず、これでDMAの実効転送レートが測定できました。Host→FPGAで6.7G Byte/sec、FPGA→Hostで5.9G Byte/secぐらいです。
Intel® アクセラレーションカードはPCI Express Gen3 x8 なので、論理転送レートと測定した実効レートを比較してみました。
表1 Intel® アクセラレーションカードのDMA転送レートの論理値と実効値の比較
| 片方向(GByte/s) | 双方向(GByte/s) | |
|---|---|---|
| PCIe Gen3の論理レート | 1.0000 | 2.0000 |
| PCIe Gen3 x8の論理レート | 8.0000 | 16.0000 |
| PCIe Gen3の実効レート | 0.9846 | 1.9692 |
| PCIe Gen3 x8の実効レート | 7.8768 | 15.7536 |
| アクセラレーションカードの実効レート(Host→FPGA) | 6.7139 | 13.428 |
| アクセラレーションカードの実効レート(FPGA→Host) | 5.9268 | 11.854 |
| 転送効率(Host→FPGA) | 85% | 85% |
| 転送効率(FPGA→Host) | 75% | 75% |
Intel® アクセラレーションカードのHost→FPGAのDMAは、一般的な同規格のPCIeカードの85%で、やや遅いかなという感じです。
特に、FPGA→HostのDMAは、一般的な同規格のPCIeカードの75%しか出ていません。これはおそらく、DMAの都度、ホスト側メモリをmemalloc(動的メモリの確保)しているためだと思われます。これは、メモリを使い回すなど、特に必要なければ行わなければいいだけの話で、実装では吸収可能と思われます。
総じて、アクセラレーションカード用ドライバーとFIU(Intel® アクセラレーションカードのPCI Expressコントローラ部分)の性能があまり出ておらず、今後最適化される部分かと思われます。
実際のアプリだとどうなるのか、動画の場合
さて、この転送レートにもう1段階踏み込んで、動画転送アプリケーションを想定した場合にどうなるか考えてみましょう。
まず、現在主流となっている映像規格ごとの必要転送レートを算出してみましょう。
表2 映像サイズごとの必要転送レート
| 規格 | X画素数 [pixel] |
Y画素数 [pixel] |
ネイティブ解像度 [pixel] |
|---|---|---|---|
| HDTV(720p) | 1,280 | 720 | 921,600 |
| HDTV(1080p) | 1,920 | 1,080 | 2,073,600 |
| 4K UHDTV | 3,840 | 2,160 | 8,294,400 |
| DCI 4K | 4,096 | 2,160 | 8,847,360 |
| 8K UHDTV | 7,680 | 4,320 | 33,177,600 |
| 画像データサイズ | 4:2:0 YCbCr 10bit [MByte] |
4:2:2 YCbCr 10bit [MByte] |
4:4:4 RGB 10bit [MByte] |
|---|---|---|---|
| HDTV(720p) | 1.65 | 2.20 | 3.30 |
| HDTV(1080p) | 3.71 | 4.94 | 7.42 |
| 4K UHDTV | 14.83 | 19.78 | 29.66 |
| DCI 4K | 15.82 | 21.09 | 31.64 |
| 8K UHDTV | 59.33 | 79.10 | 118.65 |
| 必要転送レート | 4:2:0 YCbCr 10bit 60fps [MByte/s] |
4:2:2 YCbCr 10bit 60fps [MByte/s] |
4:4:4 RGB 10bit 60fps [MByte/s] |
|---|---|---|---|
| HDTV(720p) | 98.88 | 131.84 | 197.75 |
| HDTV(1080p) | 222.47 | 296.63 | 444.95 |
| 4K UHDTV | 889.89 | 1,186.52 | 1,779.79 |
| DCI 4K | 949.22 | 1,265.63 | 1,898.44 |
| 8K UHDTV | 3,559.57 | 4,746.09 | 7,119.14 |
4:4:4はロスレスですが、あまり使われることはないフォーマットです。
4:2:2は映像素材など業務用途で使用されることが多いようです。
4:2:0はテレビ放送やDVD/BDなど最終的に配信される際に用いられています。
Intel® アクセラレーションカードの用途としては4:2:2がメインになりそうですので、これを想定します。
また、4K/8K放送が始まり、放送・配信機器が軒並み4Kにシフトする流れであるため、Intel® アクセラレーションカードでのターゲットも4K/8Kデータとなる見込みです。
先程のIntel® アクセラレーションカードのDMA性能に当てはめてみます。
図3 Intel® アクセラレーションカードの実効レートに対する使用率
| 規格 | 4:2:0 YCbCr 10bit×60fps | 4:2:2 YCbCr 10bit×60fps | 4:4:4 RGB 10bit×60fps |
|---|---|---|---|
| HDTV(720p) | 1.6% | 2.2% | 3.3% |
| HDTV(1080p) | 3.7% | 4.9% | 7.3% |
| 4K UHDTV | 14.7% | 19.6% | 29.3% |
| DCI 4K | 15.6% | 20.9% | 31.3% |
| 8K UHDTV | 58.7% | 78.2% | 117.3% |
解像度4K以下では問題ないようです。
8Kでは4:2:2であまり余裕はなく、4:4:4は帯域オーバーします。この場合、8KではIntel® アクセラレーションカードを2枚同時に使うことで実現は可能かもしれませんが、どのように処理を分割・統合させるかは処理内容によって検討する必要ありそうです。
さて、今回はIntel® アクセラレーションカードのDMA測定と、測定結果からの性能の考察を行いました。
次回はいよいよ、Intel® アクセラレーションカードにデザインを実装していきたいと思います。
個別相談も承っております。下記よりお申し込みください。



















